最近玩小程序,经常需要查看官网文档,但是官网文档个人觉得烂的不行,于是想到了用 web scraper 爬取官网数据,然后自己做个 GPT 或者 Claude Skill 来查询。以前没用过 web scraper,经过一顿学习入手,发现这东西实在太爽了。
安装 Web Scraper 插件
- Web Scraper 有官方爬取服务,只是属于付费服务,个人觉得没必要,直接用浏览器插件就行了。插件的局限性就是只能爬取网页文本数据。不过目前对于我的需求来说已经足够了。
- 官方仅提供 Chrome 浏览器插件,非 Chrome 系并没支持。
配置
个人习惯开发者工具中配置使用。
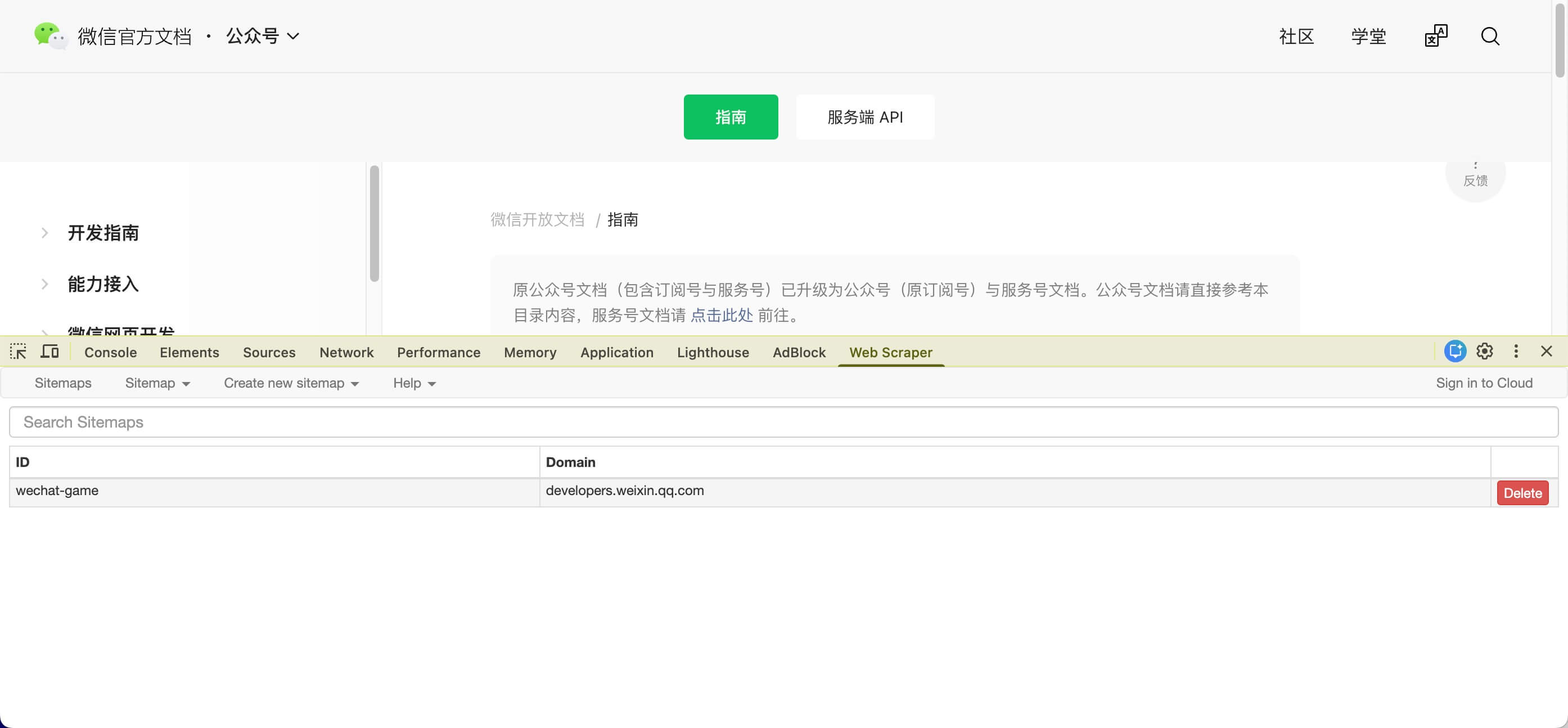
导出数据
导出目前支持 xlsx,csv,个人目前用 CSV 格式导出,方便 AI 模型使用。
AI 使用
AI 使用方法就多了,比如我这里直接 ChatGPT 下创建了一个 Custom GPT,导入数据后,就可以直接查询官网数据了。
比如我这里爬取微信小程序官网数据,然后导入 ChatGPT,构建的微信小程序官方文档小助手,你可以试试看如何。
点击这里微信小程序官方文档小助手 GPT
写在最后
对于属于爬取一般使用专门的 API,但是很多站点是屏蔽爬虫的,而 web scraper 这种浏览器插件就能很好的解决这个问题,个人觉得非常好用,推荐试试。

