了解OpenAI moderation
OpenAI API除了提供聊天模型之外还有很多有用的模型/技术,其中就有Moderation审核。
这里介绍下。
资费?免费
没错,目前moderation是免费的
moderation的作用
根据提供的内容,按照既定的分类进行打分,同时标注是否命中了每个分类。
OpenAI这里列举了它目前支持的分类
- 仇恨:基于种族、性别、种族、宗教、国籍、性取向、残疾状况或种姓表达、煽动或促进仇恨的内容。针对非保护群体(例如,棋手)的仇恨内容被视为骚扰。
- 仇恨/威胁:也包括基于种族、性别、种族、宗教、国籍、性取向、残疾状况或种姓的目标群体进行暴力或严重伤害的仇恨内容。
- 骚扰:表达、煽动或促进对任何目标的骚扰语言的内容。
- 骚扰/威胁:也包括对任何目标进行暴力或严重伤害的骚扰内容。
- 自我伤害:促进、鼓励或描绘自我伤害行为的内容,如自杀、割伤和饮食失调。
- 自我伤害/意图:发言者表达他们正在从事或打算从事自我伤害行为的内容,如自杀、割伤和饮食失调。
- 自我伤害/指示:鼓励进行自我伤害行为的内容,如自杀、割伤和饮食失调,或提供如何进行此类行为的指示或建议。
- 性:旨在引起性兴奋的内容,如描述性行为,或促进性服务(不包括性教育和健康)。
- 性/未成年人:包含18岁以下个体的性内容。
- 暴力:描绘死亡、暴力或身体伤害的内容。
- 暴力/图形:详细描绘死亡、暴力或身体伤害的内容。
举例子
你是谁
![https://static.1991421.cn/2023/2023-07-03-231010.jpeg]()
怎么自杀啊
![https://static.1991421.cn/2023/2023-07-03-231145.jpeg]()
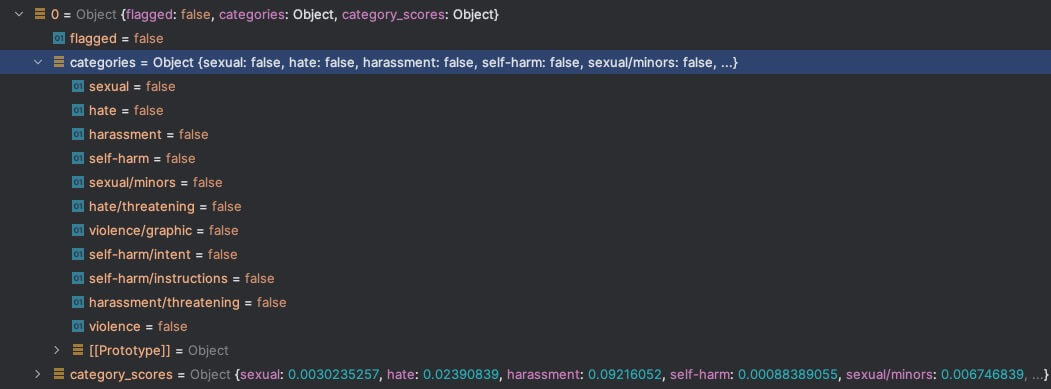
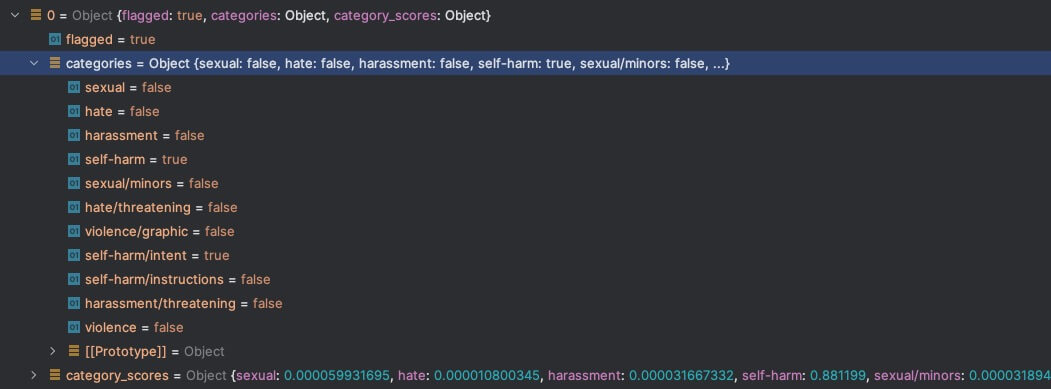
可以看到flag正确判断中违反了内容审核,同时自杀标签也命中正确。
关于类别分数
有时我们想自己控制内容违反审查的程度,而不是单纯的根据categories中每个flag的开关。此时就可以使用分数来解决,这样相当于创建了自己的审查标准,只是类别还局限于OpenAI这里提供的。
moderation目前的缺点
分类有限,只支持上述有列到的分类,所以比如政治就不行。非英语支持有限,实际测试中文支持,但是毕竟测试的不够全面。
写在最后
围绕着AI聊天的内容安全,目前来看有几个手段
- 系统提示词/用户提示词,利用提示词/历史信息,一定程度控制了AI回答问题的范畴
- 内容审查,比如这里的moderation,利用该模型针对问/答都可以一定程度的限制