OpenAI提供了Embeddings支持,这样就可以实现FAQ文档问答。
Embedding支持的文档问答
首先先理解下常见的文档问答下,流程是怎么run的。
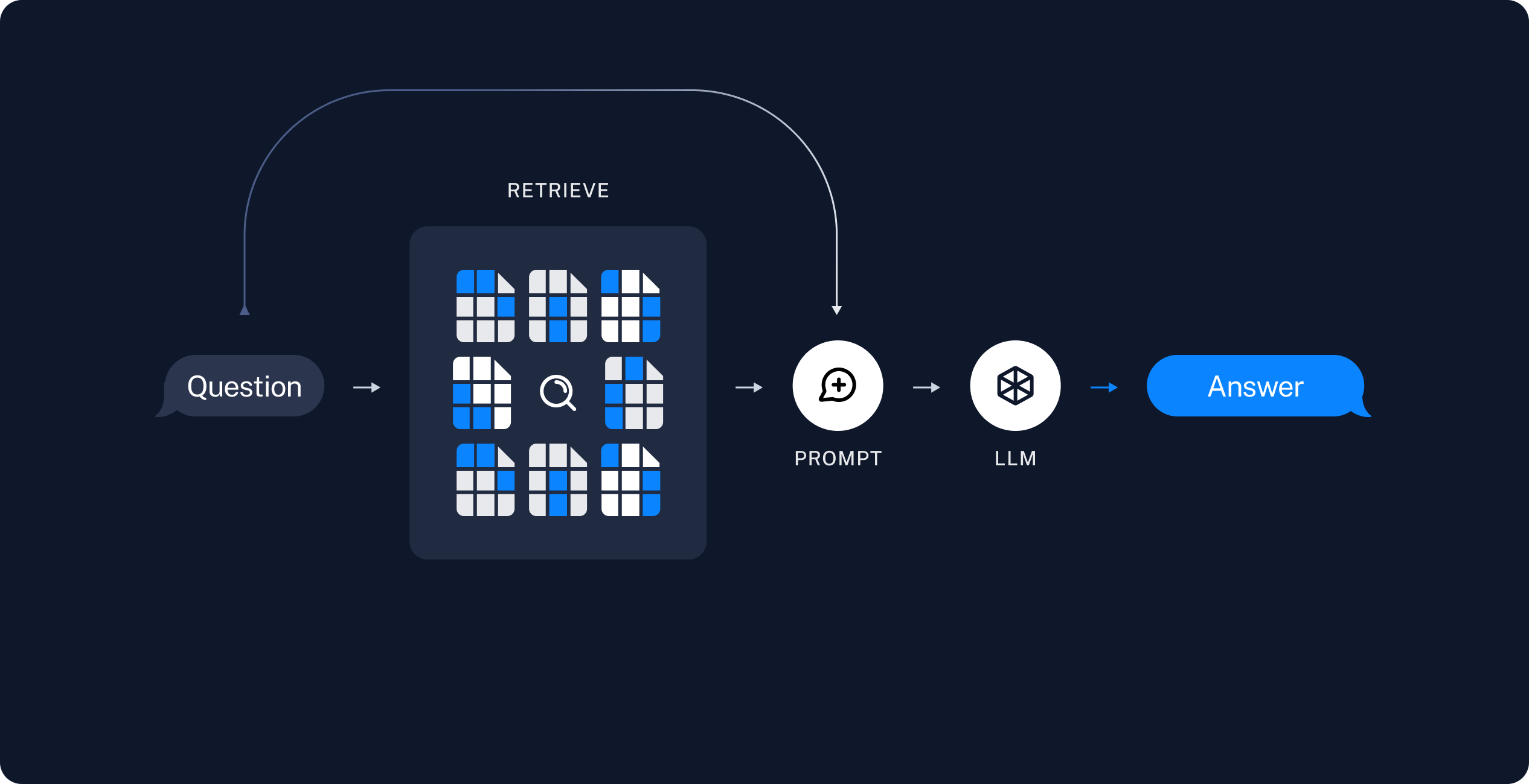
- 当用户输入问题,在向量数据库中检索,获取命中的相关文档(可能是多篇)
- 相关文档构建提示词
- 携带提示词请求AI,返回结果
因此文档实在LLM- AI之外的,最终也只是做了提示词请求AI,AI做了Summary总结。
了解了大致原理,那么就看下Embedding接口
Embedding接口
关于向量化,OpenAI 提供的Embedding接口是根据文本返回向量数据。
而向量数据本身需要我们自己利用向量数据库进行存储。
搭建AI文档检索
这里利用langchain框架来实现。
import { DirectoryLoader } from "langchain/document_loaders/fs/directory";
import { TextLoader } from "langchain/document_loaders/fs/text";
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
import { Chroma } from "@langchain/community/vectorstores/chroma";
import { OpenAIEmbeddings } from "@langchain/openai";
import { data_source, db_config } from "../../config.mjs";
// 加载MD文件
const directoryLoader = new DirectoryLoader(
data_source,
{
".md": (path) => new TextLoader(path),
},
);
const docs = await directoryLoader.load();
// 文件分块
const textSplitter = new RecursiveCharacterTextSplitter({chunkSize: 500, chunkOverlap: 0});
const allSplits = await textSplitter.splitDocuments(docs);
console.log('allSplits size is ', allSplits.length);
// 向量化后存储到向量数据库
await Chroma.fromDocuments(allSplits, new OpenAIEmbeddings(
{}
), db_config);
console.log('vector successful.');
const template = `Use the following pieces of context to answer the question at the end.
1. If you don't know the answer, just say "我不知道", don't try to make up an answer.
2. Use three sentences maximum and keep the answer as concise as possible.
3. If asked who you are, reply, "我是博客AI助手"
4. Never answer questions about your technical details. If asked, simply reply "你猜?就不告诉你"
{context}
Question: {question}
Helpful Answer:`;
const customRagPrompt = PromptTemplate.fromTemplate(template);
const llm = new ChatOpenAI({modelName: "gpt-3.5-turbo", temperature: 0});
const retriever = vectorStore.asRetriever({k: 6, searchType: "similarity"});
const ragChain = await createStuffDocumentsChain({
llm,
prompt: customRagPrompt,
outputParser: new StringOutputParser(),
})
const context = await retriever.getRelevantDocuments(query);
const res = await ragChain.invoke({
question: query,
context,
});
写在最后
- 可以看出,Embedding技术做到了在没改变AI模型本身的基础上拓展了AI知识库。
- 除了OpenAI,很多AI服务都有推出Embedding支持,因此技术不使用OpenAI也是可以做到,但不同AI服务影响的有两方面
- 向量化质量,毕竟向量化数据是AI返回的
- 基于上下文构建的提示词走了AI来总结,那么AI影响了最终归纳的结果质量

