腾讯云API文档docset
·
2 min read
工作中经常需要查询腾讯云API文档,为了提高检索效率,决定制作成dash-docset,毕竟dash下进行文档搜索还是高效的。
这里总结下制作流程
效果
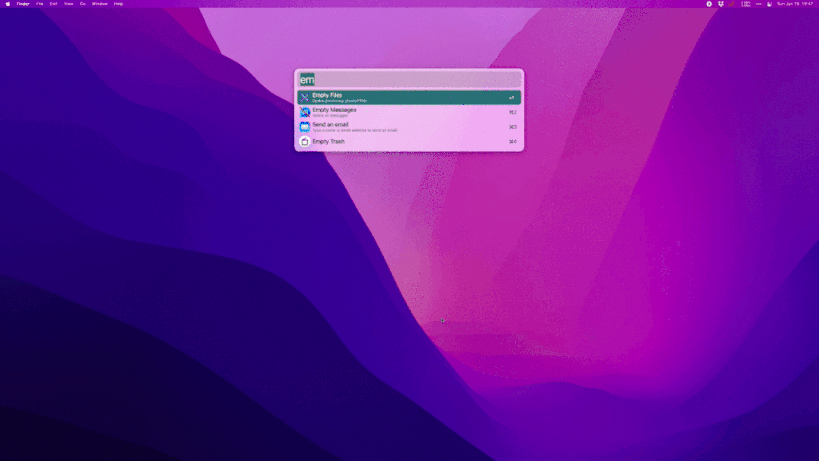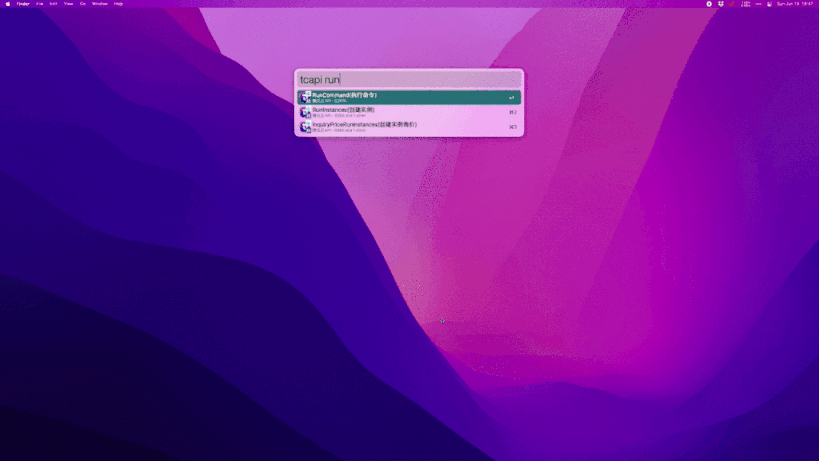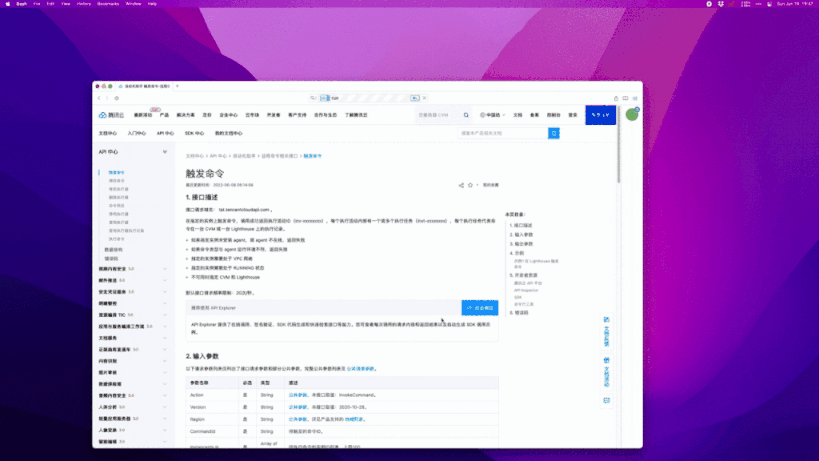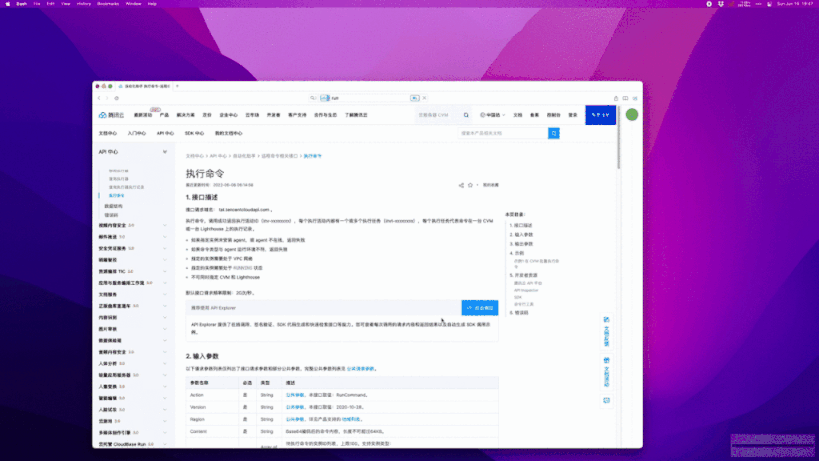
原理
- 爬虫爬取腾讯云API文档,保存为HTML网页
- dash下无论是官方提供的docset还是社区贡献的,本质都是爬取的文档网页或者直接使用的文档MD文件,MD文件的好处是结构简单,更易于加工处理
- 腾讯云API文档没有开源MD文件等,因此这里只能选择爬取网页
- 递归解析所有网页,提取interface/function等信息,网页名称及层级可以逆向获取在线URL路径
- 网页结构只要规范,解析问题并不大
- 提取的信息按照dash官方提供的数据结构进行存取,最终打包为docset即可
确定了基本的方向就可以上手制作了。
制作
关于爬取网页,目前采用wget命令,该命令支持递归抓取,
- 注意curl不支持递归,因此不考虑
按照dash要求创建文档结构及sqllite数据表
利用Node.JS解析HTML文件获取元数据信息,逐行插入DB中
- 一开始考虑解析完所有文档再批量插入,但文档过多容易造成内存溢出,因此这里采取每个文档解析完,执行一次批量插入数据
- dash支持浏览本地文档或者在线文档,本地文档的好处是排版完全可控,相反在线文档的只托管了网址,但排版就不可控了。这里为了简单,因此只托管了网址,无论是首页还是各个API网页均直接访问的在线网址。
执行tar打包命令
编写feed.xml文件,从而方便他人订阅
- dash中同步并不会同步加载的本地docset,因此如果是多设备共享docset,这里需要制作成feed,其它设备订阅即可,当然也可以按照官方推荐的提交到官方仓库中。
整体制作脚本及docset都托管在了这里-dash-docset-tcapi
写在最后
- 该方案主要解决了关键词快速检索定位文档URL,最终还是dash内的网页浏览。如上所说也可以处理做到本地文档浏览,但这样就意味着文档可能会有出入并非最新的,同时排版/样式需要特殊处理解决,URL还是本地文档需要看需求解决
- 类似API方面的文档检索如果没有现成的docset,均可以采用此方案来解决。