Java日志管理及运维分析
项目上线后,每次遇到系统来回调用的问题,QA,BA往往需要询问开发,而开发先查代码,日志记录关键词,进而到kibana中进行检索,同时由于日志记录量大,还需要各种操作筛选等。最终可能问题的解决只花费了10分钟,但是确定到目标日志却花费了30分钟以上。之后再出现问题,又要进行这样一个流程,费时费力。
冷静看待这样的一个问题发生时的排查流程,会发现,多个环节完全可以规范及自动化,即存在优化空间。
日志系统技术栈
在进行优化前,先了解下,当前我们项目日志方面的技术栈

- logback
记录 - logstash
收集 - kibana
查看
日志记录的几条原则
阿里巴巴Java开发手册(泰山版)还是不错的,推荐大家看下。当然最终还要因地制宜。
这里列举几条个人更为看重的。
- 业务日志与异常日志分开
- 尽量用英文来描述日志错误信息,如果日志中的错误信息用英文描述不清楚的话使用中文描述即可,否则容易产生歧义。
- 异常没有处理,就要向上抛
Java中日志记录
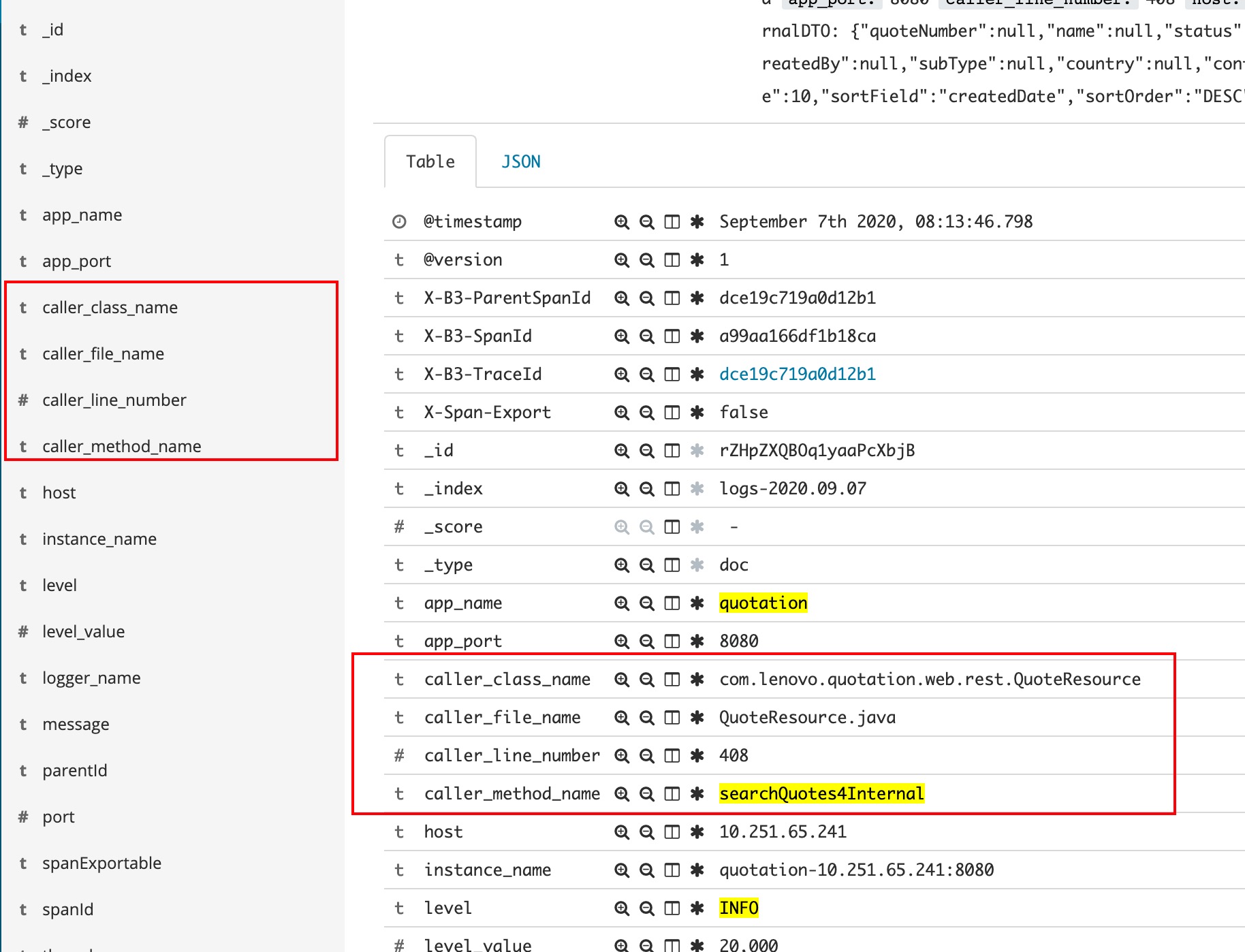
类名称,方法名,行号日志关键词
比如下面的日志记录
1 | log.info("quoteId: {} response: {}", quoteId, JsonConverter.serializeObject(quoteWithSaleRegDTO)); |
日志配置
Console配置
1 | logging: |
logstash配置
1 | logstashEncoder.setIncludeCallerData(true) |
详细配置戳这里
注意
- Kibana中的日志元数据取决于logstash配置,logback配置只是解决了控制台日志打印,两者还不同
- 日志也是代码的一部分,与注释相同,当量增加,维护成本也增加,所以比如方法名称,行号这些都是强相关,但又是变量,所以能自动,坚决不要手写。
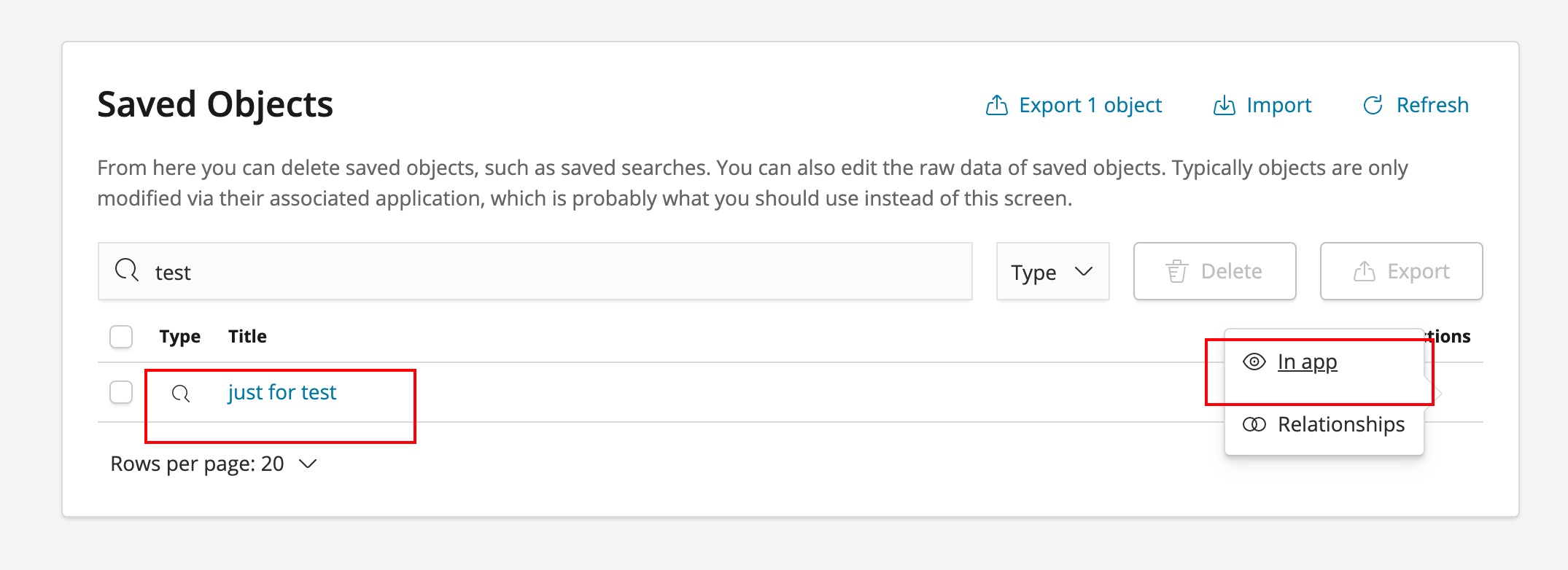
kibana中日志查看
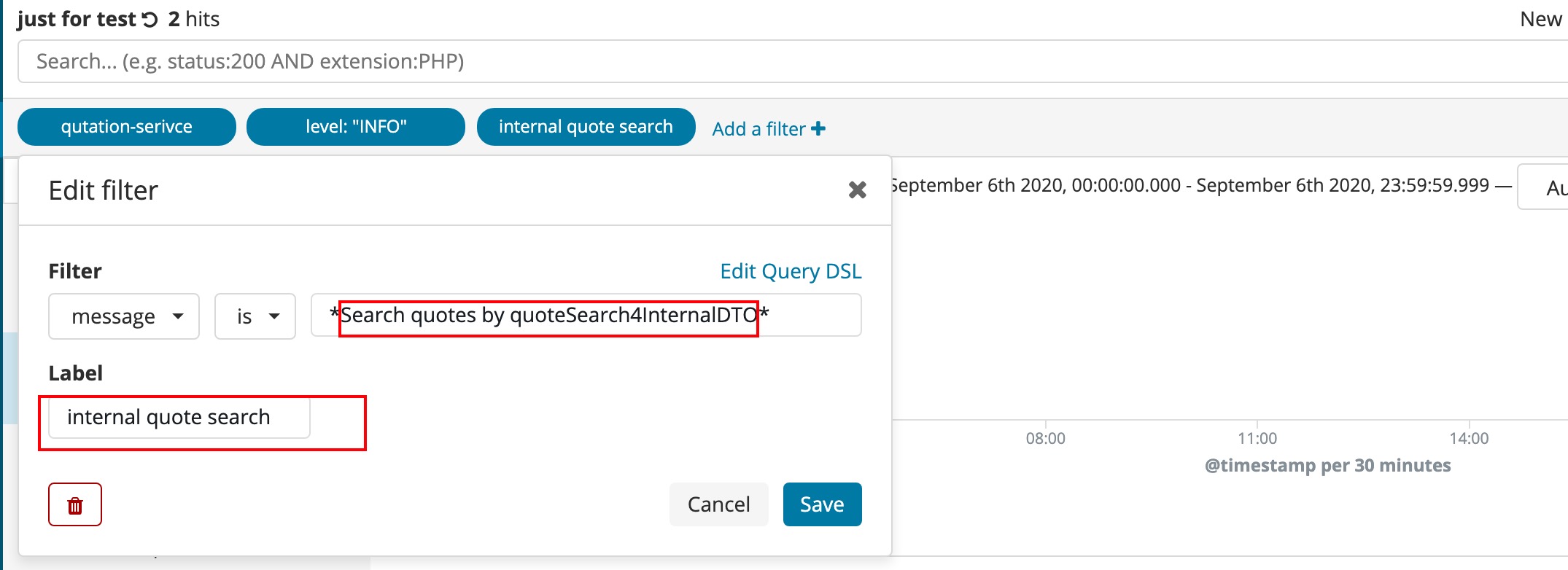
每次特定业务功能的查询如果都是重新去配置实际上是很浪费时间的,kibana提供了save功能,所以较好的方式是我们将经常进行的检索条件存储,同时,对于条件利用label描述进行说明即可。
注意
- label进行条件的描述,这样方便理解
- 日志的时间区间及自动刷新也很重要,辅助快速问题发生时间段的日志
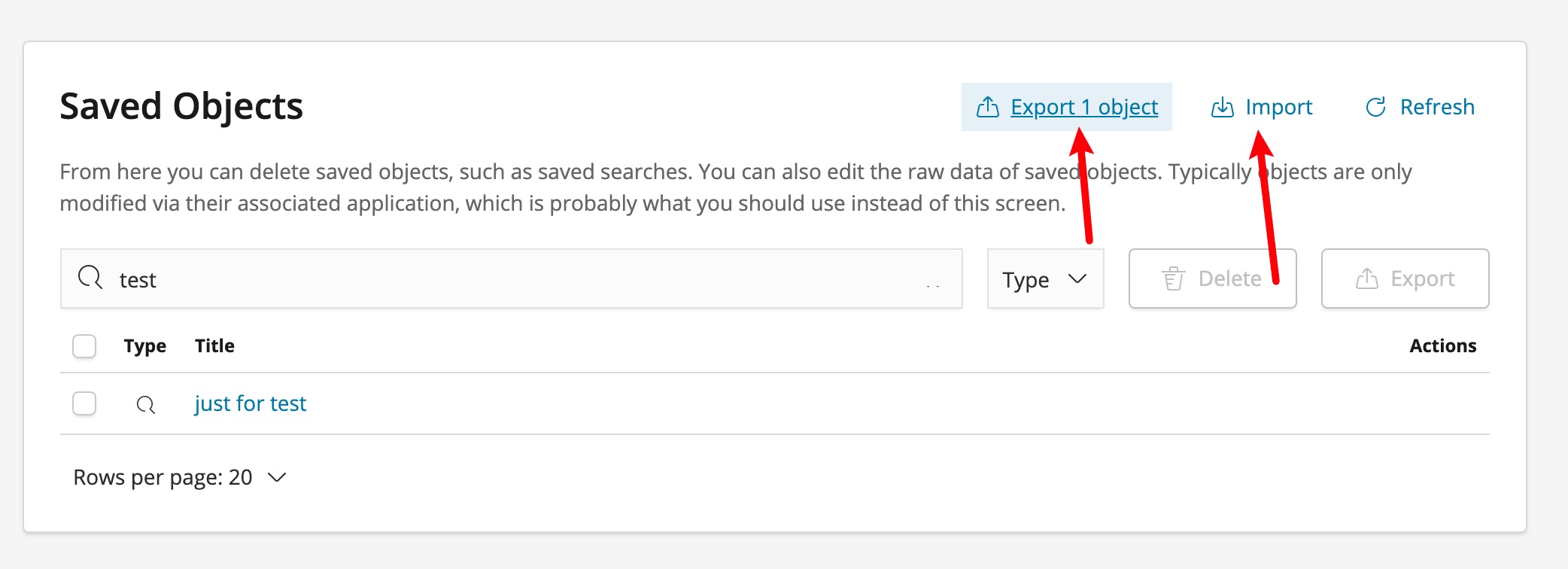
- 不同环境我们需要快速同步共享搜索配置,那么可以导入导出解决,这样就不必每个环境系统重新配置。
- callerData暴露的method,class等字段也可以进行检索筛选,但对于kibana新增的字段,需要先执行下 management=》index patterns=>Refresh field list,才可以用于筛选检索
写在最后
- 日志在一个产品上线后面对种种问题,进行排查追溯时发挥着重要的作用。因此重视日志,一个手段是结构化日志信息,比如上述的类名称,方法名称,行号,及主观注入的关键词变量等。另一个手段当然就是日志的检索上,利用工具来优化提速查询效率。
- 看到一些同事盲目的在写日志,就像面对注释的方式一些,要知道,注释,日志都是代码的一部分,写了就存在维护代价,所以要适度,适量,科学即可。