
最近在群里刷题看到这样一个问题
'✈️'.length,额,一脸懵逼,于是开始查找资料,系统了解,这里Mark下。
emoji是啥
emoji(英语:emoji,日语:絵文字/えもじ emoji),是使用在网页和聊天中的形意符号
- 我们输入的表情,并不是图片,而是实实在在的字符
- Twitter,iOS,Windows
同一个表情,但是长的却不一样,因为字符只是规定了码点,码位,存储,但是具体展示的样子由各个平台-各个字体决定
字符编码
在搞明白'✈️'.length之前,先补下编码知识
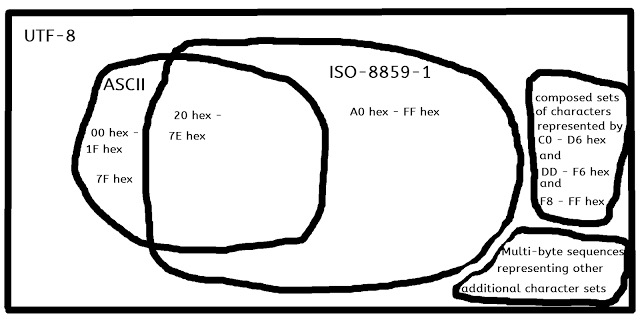
我们常说的编码有这些。ASCII(国际编码),Unicode(国际符号集),UTF8(国际编码),GB2312(国标编码),ISO-8859-1(国际编码)
记得以前,经常遇见编码的问题,解压缩,浏览网页,上传下载各种编码,乱码问题,但是今天这个问题并不常见了。why?因为这个也在发版中。
- ASCII只考虑了英文字符
- Unicode考虑了世界上各种字符,符号,规定了符号的二进制代码
- Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码 应该如何存储
UTF-8是Unicode的实现方式之一,一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度- Unicode 编码范围是从 U+0000 到 U+10FFFF,每一个编码(也称之为码位 code point)表示一个 Unicode 字符;而这么多码位有划分成 17 个平面: 第一个平面(U+0000 ~ U+FFFF): 基本平面(Basic Multilingual Plane - BMP) 其他 16 个平面(U+100000 ~ U+10FFFF): 补充平面(Supplementary Planes)
- GB2312是
国标,但是今天几乎所有站点都是UTF8,GB2312已经被淘汰。 - ISO-8859-1 不是Unicode字符集,原因是并不对所有符号编码,只是一部分,今天也很少见该编码
- JavaScript 引擎内部是自由的使用 UCS-2 或者 UTF-16
- Java默认编码方式是UTF-16
下图可以简单的看出几种编码的区别,以后应该主要是UTF了
emoji长度
编码知道后,再一开始的长度疑问
- 比如JS里
'123'.length===3这里的长度是字符串长度,也就是包含的字符个数 字符数,字节数,string length并不等价- 不同的emoji表情,代表的字符数是不同的
Unicode与emoji
- 基本平面内的emoji,字符长度是1
- 基本平面内的多字符,字符长度是2
- 补充平面内的单字符,字符长度是2
- 补充平面内的多字符,字符长度不确定
- 多个Emoji字符,字符长度不确定
举个例子
// 各个表情字符个数
console.log('⛷'. length); // 1
console.log('😂'.length); // 2
console.log('1️⃣'.length); // 3
console.log('👨👨👦'.length); // 8
console.log('👨👩👧👦'.length); // 11
日常接触到的编码
系统编码,终端中输入
locale即可看到系统编码搞开发的同学会看到IDE,各个程序文件都有文件编码,DB也有database编码
浏览器浏览网页HTML,CSS,JS也都有对应的编码
终端显示文本信息,或者emoji也是编码及支持emoji编码的字体,假如乱码,也就知道了maybe是当前字体对于emoji编码不支持,换个字体即可。
写在最后
虽然搞明白了这些编码的关系,了解了丰富的emoji表情背后的原理。but,我似乎还是无法看到一个表情,就知道占用几个字符,存储占用几个自己,😭。
参考文档
- Emoji 简介
- 字符编码笔记:ASCII,Unicode 和 UTF-8
- GB2312
- The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)
- Emoji Unicode Tables
- Javascript 有个 Unicode 的天坑
- 探究 emoji 字符长度
- emoji WIKI
- utf-8编码已经成为主流
- 探索iOS中Emoji表情的编码与解析
- JavaScript’s internal character encoding: UCS-2 or UTF-16?